
Да се вратиме на суштината, пробивот на AIGC во сингуларноста е комбинација од три фактори:
1. GPT е реплика на човечки неврони
GPT AI претставена со NLP е компјутерски невронски мрежен алгоритам, чија суштина е да симулира невронски мрежи во човечкиот церебрален кортекс.
Обработката и интелигентната имагинација на јазикот, музиката, сликите, па дури и информациите за вкусот се функции акумулирани од човекот
мозокот како „протеински компјутер“ за време на долготрајната еволуција.
Затоа, GPT е природно најсоодветната имитација за обработка на слични информации, односно неструктурирани јазик, музика и слики.
Механизмот на неговата обработка не е разбирање на значењето, туку процес на рафинирање, идентификување и поврзување.Ова е многу
парадоксална работа.
Раните алгоритми за семантичко препознавање на говор во суштина воспоставија граматички модел и говорна база на податоци, а потоа го мапираа говорот со вокабуларот,
потоа го ставаат вокабуларот во граматичката база на податоци за да го разберат значењето на вокабуларот и конечно се добиваат резултати од препознавање.
Ефикасноста на препознавање на овој синтаксно препознавање базирано на „логички механизам“ лебди околу 70%, како што е препознавањето ViaVoice
алгоритам воведен од IBM во 1990-тите.
АИГЦ не сака да игра вака.Нејзината суштина е да не се грижи за граматиката, туку да воспостави алгоритам на невронска мрежа кој овозможува
компјутер да ги брои веројатните врски помеѓу различни зборови, кои се нервни врски, а не семантички врски.
Слично како учењето на нашиот мајчин јазик кога бевме млади, ние природно го научивме, наместо да учиме „предмет, прирок, предмет, глагол, дополнување“.
а потоа разбирање на параграф.
Ова е модел на размислување на вештачката интелигенција, што е препознавање, а не разбирање.
Ова е и субверзивното значење на вештачката интелигенција за сите модели на класични механизми - компјутерите не треба да ја разберат оваа работа на логично ниво.
туку идентификувајте ја и препознајте ја корелацијата помеѓу внатрешните информации, а потоа запознајте ја.
На пример, состојбата на протокот на моќност и предвидувањето на енергетските мрежи се засноваат на класичната симулација на енергетската мрежа, каде што математички модел на
механизмот се воспоставува и потоа се конвергира со помош на алгоритам на матрица.Во иднина, можеби нема да биде потребно.ВИ директно ќе идентификува и предвидува a
одредена модална шема заснована на статусот на секој јазол.
Колку повеќе јазли има, толку помалку е популарен алгоритамот на класичната матрица, бидејќи сложеноста на алгоритмот се зголемува со бројот на
јазли и геометриската прогресија се зголемува.Сепак, вештачката интелигенција претпочита да има истовременост на јазли во многу големи размери, бидејќи вештачката интелигенција е добра во идентификувањето и
предвидување на најверојатните мрежни режими.
Без разлика дали тоа е следното предвидување на Go (AlphaGO може да ги предвиди следните десетици чекори, со безброј можности за секој чекор) или модалното предвидување
на сложени временски системи, прецизноста на вештачката интелигенција е многу повисока од онаа на механичките модели.
Причината зошто електричната мрежа моментално не бара вештачка интелигенција е тоа што бројот на јазли во енергетските мрежи од 220 kV и повеќе управувани од провинциски
испраќањето не е големо, а многу услови се поставени да ја линеаризираат и ретки матрицата, значително намалувајќи ја пресметковната сложеност на
модел на механизам.
Меѓутоа, во фазата на проток на моќност на дистрибутивната мрежа, соочена со десетици илјади или стотици илјади јазли на моќност, јазли за оптоварување и традиционални
матрични алгоритми во голема дистрибутивна мрежа е немоќна.
Верувам дека препознавањето на шаблонот на ВИ на ниво на дистрибутивна мрежа ќе стане возможно во иднина.
2. Акумулација, обука и генерирање на неструктурирани информации
Втората причина зошто AIGC направи пробив е акумулацијата на информации.Од A/D конверзија на говор (микрофон+PCM
земање примероци) до А/Д конверзија на слики (CMOS+мапирање на просторот во боја), луѓето имаат акумулирано холографски податоци во визуелниот и аудитивниот
полиња на екстремно евтини начини во изминатите неколку децении.
Особено, големата популаризација на камерите и паметните телефони, акумулацијата на неструктурирани податоци во аудиовизуелното поле за луѓето
по речиси нула цена, а експлозивната акумулација на текстуални информации на Интернет се клучот за обуката на AIGC – збирките на податоци за обука се евтини.
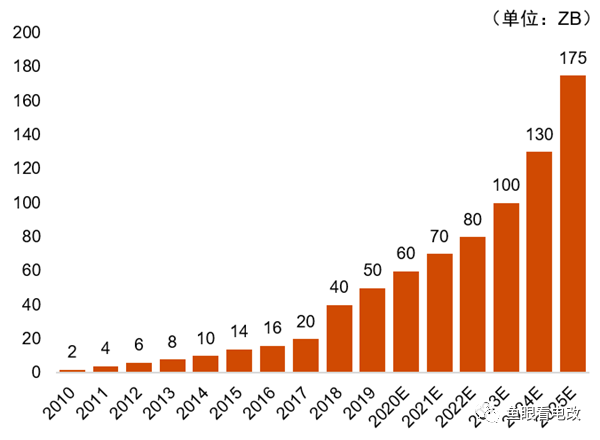
Сликата погоре го покажува трендот на раст на глобалните податоци, што јасно претставува експоненцијален тренд.
Овој нелинеарен раст на акумулацијата на податоците е основа за нелинеарниот раст на способностите на AIGC.
НО, повеќето од овие податоци се неструктурирани аудио-визуелни податоци, кои се акумулираат со нула трошоци.
Во областа на електричната енергија тоа не може да се постигне.Прво, поголемиот дел од електроенергетската индустрија се структурирани и полуструктурирани податоци, како на пр
напон и струја, кои се точки на податоци од временски серии и полуструктурирани.
Структурните множества на податоци треба да ги разберат компјутерите и бараат „усогласување“, како што е усогласување на уредите - податоци за напонот, струјата и моќноста
на прекинувачот треба да се порамни со овој јазол.
Попроблематично е усогласувањето на времето, кое бара усогласување на напонот, струјата и активната и реактивна моќност врз основа на временската скала, така што
може да се изврши последователна идентификација.Исто така, постојат насоки напред и назад, кои се просторно усогласување во четири квадранти.
За разлика од текстуалните податоци, за кои не е потребно усогласување, параграфот едноставно се фрла на компјутерот, кој ги идентификува можните асоцијации на информации
сам по себе.
За да се усогласи ова прашање, како што е усогласувањето на опремата на податоците за деловната дистрибуција, постојано е потребно усогласување, бидејќи медиумот и
нисконапонската дистрибутивна мрежа секојдневно додава, брише и менува опрема и линии, а мрежните компании трошат огромни трошоци за работна сила.
Како „прибелешка на податоци“, компјутерите не можат да го направат тоа.
Второ, трошоците за стекнување податоци во енергетскиот сектор се високи, а потребни се сензори наместо мобилен телефон за зборување и фотографирање.”
Секој пат кога напонот се намалува за едно ниво (или врската со дистрибуција на електрична енергија се намалува за едно ниво), потребната инвестиција на сензорот се зголемува
барем по еден ред на големина.За да се постигне сензор од страна на товарот (капиларен крај), тоа е уште помасовна дигитална инвестиција.“
Доколку е неопходно да се идентификува преодниот режим на електричната мрежа, потребно е високо-прецизно високофреквентно земање мостри, а цената е уште поголема.
Поради екстремно високиот маргинален трошок за стекнување податоци и усогласување на податоците, електричната мрежа моментално не може да акумулира доволно нелинеарни
раст на информации за податоци за да се обучи алгоритам да ја достигне сингуларноста на ВИ.
Да не зборуваме за отвореноста на податоците, невозможно е стартап со моќна вештачка интелигенција да ги добие овие податоци.
Затоа, пред вештачката интелигенција, неопходно е да се реши проблемот со збирките на податоци, инаку генералниот код на вештачката интелигенција не може да се обучи за да произведе добра вештачка интелигенција.
3. Пробив во пресметковната моќ
Покрај алгоритмите и податоците, пробивот на сингуларноста на AIGC е и пробив во пресметковната моќ.Традиционалните процесори не се
погоден за истовремени невронски пресметувања од големи размери.Токму примената на графичкиот процесор во 3D игри и филмови е она што прави паралела во големи размери
Можно е подвижна запирка + стриминг компјутери.Муровиот закон дополнително го намалува пресметковниот трошок по единица пресметковна моќност.
Енергетска мрежа AI, неизбежен тренд во иднина
Со интегрирање на голем број дистрибуирани фотоволтаични и дистрибуирани системи за складирање енергија, како и барањата за примена на
виртуелни електрани од страна на оптоварувањето, објективно е неопходно да се спроведе прогноза на изворот и оптоварувањето за системите на јавната дистрибутивна мрежа и корисникот
дистрибутивни (микро) мрежни системи, како и оптимизација на протокот на моќност во реално време за дистрибутивни (микро) мрежни системи.
Комплексноста на пресметката на страната на дистрибутивната мрежа е всушност поголема од онаа на распоредот на преносната мрежа.Дури и за реклама
комплекс, може да има десетици илјади уреди за оптоварување и стотици прекинувачи, како и побарувачката за работа на микро-мрежа/дистрибутивна мрежа базирана на вештачка интелигенција
ќе се појави контрола.
Со ниската цена на сензорите и широката употреба на енергетски електронски уреди како што се трансформатори со цврста состојба, прекинувачи со цврста состојба и инвертери (конвертори),
интеграцијата на сензори, пресметување и контрола на работ на електричната мрежа, исто така, стана иновативен тренд.
Затоа, AIGC на електричната мрежа е иднината.Меѓутоа, она што е потребно денес не е веднаш да се извади алгоритам за вештачка интелигенција за да се заработат пари,
Наместо тоа, прво разгледајте ги проблемите со изградбата на податочната инфраструктура што ги бара вештачката интелигенција
Во подемот на AIGC, треба да има доволно мирно размислување за нивото на примена и иднината на моќната вештачка интелигенција.
Во моментов, значењето на моќната вештачка интелигенција не е значајно: на пример, фотоволтаичен алгоритам со точност на предвидување од 90% се пласира на самото место на пазарот.
со праг на отстапување од тргување од 5%, а отстапувањето на алгоритмот ќе ги избрише сите профити од тргувањето.
Податоците се вода, а пресметковната моќ на алгоритмот е канал.Како што ќе се случи, така ќе биде.
Време на објавување: Мар-27-2023